Detecting Emerging Concepts
in Textual Data Mining
William
M. Pottenger, Ph.D. and David R. Gevry
Lehigh
University
Recent advances in computer technology are fueling radical changes in the nature of information management. Increasing computational capacities coupled with the ubiquity of networking have resulted in widespread digitization of information, thereby creating fundamentally new possibilities for managing information. One such opportunity lies in the budding area of textual data mining. With roots in the fields of statistics, machine learning and information theory, data mining is emerging as a field of study in its own right. The marriage of data mining techniques to applications in textual information management has created unprecedented opportunity for the development of automatic approaches to tasks heretofore considered intractable. This document briefly summarizes our research to date in the automatic identification of emerging trends in textual data. We also discuss the integration of trend detection in the development of constructive, inquiry-based multimedia courseware.
The process of detecting emerging conceptual content that we envision is analogous to the operation of a radar system. A radar system assists in the differentiation of mobile vs. stationary objects, effectively screening out uninteresting reflections from stationary objects and preserving interesting reflections from moving objects. In the same way, our proposed techniques will identify regions of semantic locality in a set of collections and ‘screen out’ topic areas that are stationary in a semantic sense with respect to time. As with a radar screen, the user of our proposed prototype must then query the identified ‘hot topic’ regions of semantic locality and determine their characteristics by studying the underlying literature automatically associated with each such ‘hot topic’ region.
Applications of trend detection in textual data are numerous: the detection of such trends in warranty repair claims, for example, is of genuine interest to industry. Technology forecasting is another example with numerous applications of both academic and practical interest. In general, trending analysis of textual data can be performed in any domain that involves written records of human endeavors whether scientific or artistic in nature.
Trending of this nature is primarily based on
human-expert analysis of sources (e.g., patent, trade, and technical
literature) combined with bibliometric techniques that employ both semi and
fully automatic methods [White and McCain 1989]. Automatic approaches have not
focused on the actual content of the literature primarily due to the complexity
of dealing with large numbers of words and word relationships. With advances in
computer communications, computational capabilities, and storage
infrastructure, however, the stage is set to explore complex interrelationships
in content as well as links (e.g., citations) in the detection of
time-sensitive patterns in distributed textual repositories.
Semantics are, however, difficult to identify unambiguously. Computer algorithms deal with a digital representation of language – we do not have a precise interpretation of the semantics. The challenge thus lies in mapping from this digital domain to the semantic domain in a temporally sensitive environment. In fact, our approach to solving this problem imbues semantics to a statistical abstraction of relationships that change with time in literature databases.
Our research objective is to design, implement, and validate a prototype for the detection of emerging content through the automatic analysis of large repositories of textual data. In this project in particular, we are interested in applying trend detection algorithms as a textual data mining tool that will aid students in learning through constructive exercises.
The following steps are involved in the process: concept identification/extraction; concept co-occurrence matrix formation; knowledge base creation; identification of regions of semantic locality; the detection of emerging conceptual content; and a visualization depicting the flow of topics through time. For details on our approach, please see [Pottenger and Yang 2000] and [Bouskila and Pottenger 2000].
The integration of our Hot Topics Data Mining System in constructive, inquiry-based multimedia requires sophisticated lesson tracking and context construction mechanisms that are described in more detail below.
Lesson Tracking and Context Enhancement
The research that is being done in this area is two fold. The first focus of this project is to track users as they move through the lessons and determine how individual users as well as users as a group approach the lessons. The goal is to use individual users’ contexts to enhance their performance when conducting constructive, inquiry-based learning exercises that employ the Hot Topics Textual Data Mining System to uncover trends in a given field of study.
The motivation for this tracking research comes from our current work with user profiling based on temporal aspects of web access: how often a user visits a page and how long they stay on that page. The goal of the research is to link users’ temporal data with the semantic data of the documents that they view. This temporal link will allow us to automatically filter a model of the user’s interests based on their history of access to the material. The first step in this research is thus to gather source data for individual user access.
Initially this user profiling research began by examining server web logs in order to profile individual users – unfortunately this data did not work for our purposes. The logs that we were using did not contain enough information to distinguish individual users. For example, given an IP address it is hard to determine whether the user is a distinct person or a number of users who are using the same address (e.g., a proxy server). In the logs we studied[1] the reported value for the operating system changed for an individual address in many cases. IP address look-up of these addresses revealed that the majority of the addresses were proxy servers or similar gateways, hence invalidating them as individual users for our purposes.
Another reason why these logs files were not useful for the research was due to the sparseness of individual user access. Users did not seem to frequent the site for very long, and during the two week period of time we chose, few users made repeat visits to the site. Below is a chart that depicts user access in a continuous five-day period. In order for temporal user profiling to be effective there must be sufficient data to characterize the user’s browsing activities. The web server logs however cannot provide us with this type of data because users do not frequent the site enough to yield adequate temporal data.
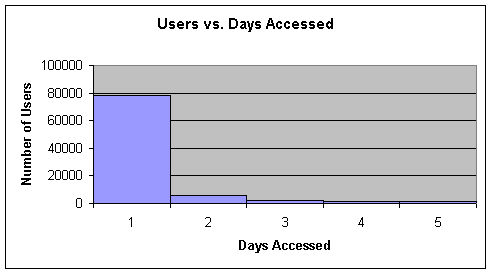
These factor compounded by the uncertainty of identifying individual users caused us to abandon these logs as a viable source of data for our research.
In response to this issue we devised an approach to track the usage of multimedia courseware. We believe that tracking lessons in this way will yield us with a larger source of individual user data. The nature of the lessons themselves will promote user access, and we will be able to track these individual users as they progress through the lessons. Although this data will not be representative of individual user web access it will provide us with interesting representations on how students use and access the data as well as possible temporal relationships with user interest. Additionally it will assist in locating spots inside the lessons themselves where individuals or groups of users spend a significant amount of time, and this will allow us to determine possible points of interest or confusion in understanding the material. The users will have round-the-clock access to the lessons and therefore tracking individual access will give us a better picture of a user’s interest and what parts of the lessons the user found useful in studying the material, working homework exercises, studying for exams, etc.
Our focus will be to generate temporally sensitive contexts specific to individual users, and to boost the performance of the Hot Topics Textual Data Mining System using these contexts. By tracking the user we plan to build the context within which they are conducting constructive, inquiry-based learning exercises that employ the Hot Topics Textual Data Mining System. The data will be used to generate time sensitive contexts to focus the nature of the detection of emerging topics in the field being studied. Time sensitive contexts will be compared to an unmodified general context for the course to see if focusing on what the user has examined in a given timeframe is more effective in identifying ‘hot topics’ relevant to the constructive, inquiry-based exercises. To aid the Hot Topics Textual Data Mining System we will generate a repository of documents related to the topic area under study. This will give a more focused conceptual space from which to draw when performing ‘hot topics’ detection.
Finally, though not directly related to this project, an individual proxy system will be implemented to gain a second, more general dataset of user profiles. This will involve routing participants’ web browsers through a proxy server placed on their machine. The log files generated by this system will have the benefit of being specific to a user and will give a better picture of user browsing patterns and interests in a temporal sense.
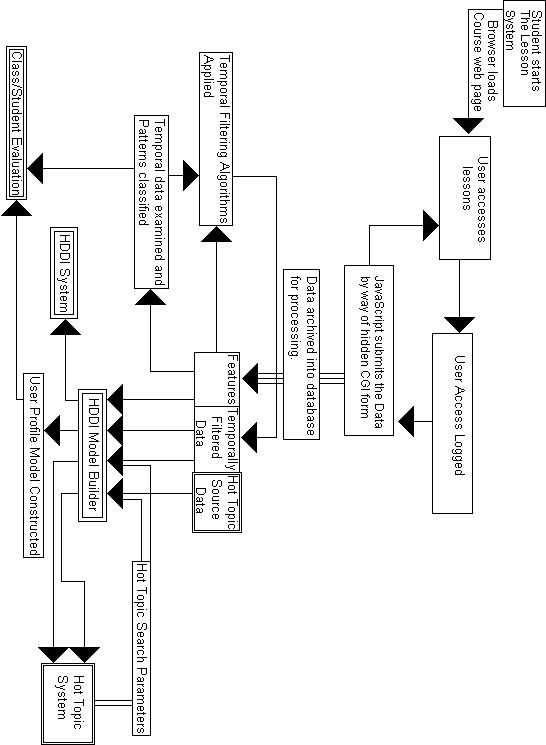
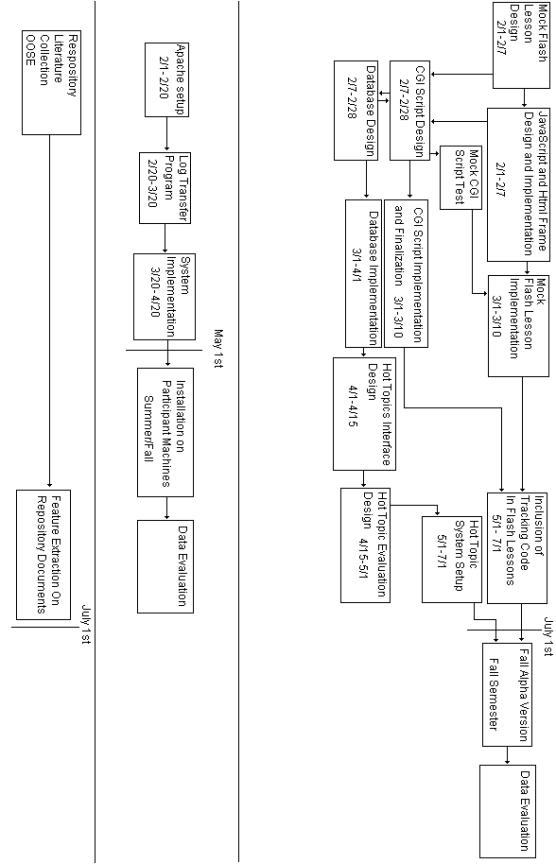
Given below is a use-case diagram for the Lesson Tracking and Hot Topics Textual Data Mining System as well as a timeline for our research. The use-case diagram shows the pathways through the proposed system we will design. The user’s actions will be tracked through JavaScript functions that will communicate to our database through a CGI script. The database will also contain additional content information for the lessons and this will be combined with the temporal data to form a temporally sensitive contextual model that will be used by the Hot Topics Textual Data Mining System to augment its performance. The timeline is broken into separate timelines for the Lesson Tracking and Hot Topics Textual Data Mining System, proxy tracking, and collection development and management for the repository encompassing the field of study.